
����� vs �����_���t�H���X�g�F���Ă͂܂�Ɖ��߂��ǂ��I�ԁH�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z

���v�I����ƃ����_���t�H���X�g�͕����̗v���Ń^�[�Q�b�g��\�����郂�f���ŁA���v�I����̓f�[�^���番����v�Z�����߂�����ꍇ�����邪�A�r�W�l�X���߂�e�Ղɂ�����@������A�����_���t�H���X�g�͉��߂�������f�[�^�ւ̓��Ă͂܂肪�����B���Ă͂܂�Ɖ��߂̃o�����X���l�������͎�@��I������B
![]() ����������������
����������������
�`�����l���o�^�͂�����
�ڎ� ����� vs �����_���t�H���X�g�F���Ă͂܂�Ɖ��߂��ǂ��I�ԁH�y��������w�E���R�z��Y���m��AI�ް����ݽ�u���z
���v�I����ƃ����_���t�H���X�g
���v�I����A�����_���t�H���X�g���g���Ă݂悤
���Ă͂܂�Ɖ��߂̂ǂ����D�悷�邩�����߂āA�쐬���悤
���v�I������������_���t�H���X�g���A�����̗v�����ڂłP�̃^�[�Q�b�g���ڂ�\�����f������邱�Ƃ��ł��܂��B
���v�I����́A�f�[�^����̕�����v�Z���邽�߁A�����Ή�����Ɩ��m���̏펯�Ƃ͈�����������o�āA���߂ɖ������Ƃ�����܂��B
���̌����́A���v�I������A�^�[�Q�b�g���ڂ��œK�ɕ�����W�c���A�f�[�^������Ƃ������@�ŕ�����v�Z���Ă��邩��ł��B
�f�[�^�𒆗��I�ɕ��͂����ꍇ�̍œK�Ȍ��ʂ��A���v�I������o���Ă��܂��B
�r�W�l�X���߂����₷������ɂ���ꍇ�́A���v�I����ŏo�����ʂ��Q�l�ɂ��ĉ����ɉ����ĕ�������A�������蒼���Ƃ����ł��傤�B
���̏ꍇ�A���v�I����ŏo�����ʂ����f�[�^�̓��Ă͂܂�͈����Ȃ�܂��B
���f���̃f�[�^�ւ̓��Ă͂܂�ƁA���߂̂��₷���͈�ʓI���g���[�h�I�t�Ȃ̂ŁA���Ă͂܂�Ɖ��߂̂��₷���̂ǂ����D�悵�ĕ��͂��邩�ɂ���ĕ��͎�@��ς��܂��B
�����_���t�H���X�g�́A���v�I��������߂͂��ɂ����ł����A�f�[�^�ւ̓��Ă͂܂�͗ǂ��Ȃ�܂��B
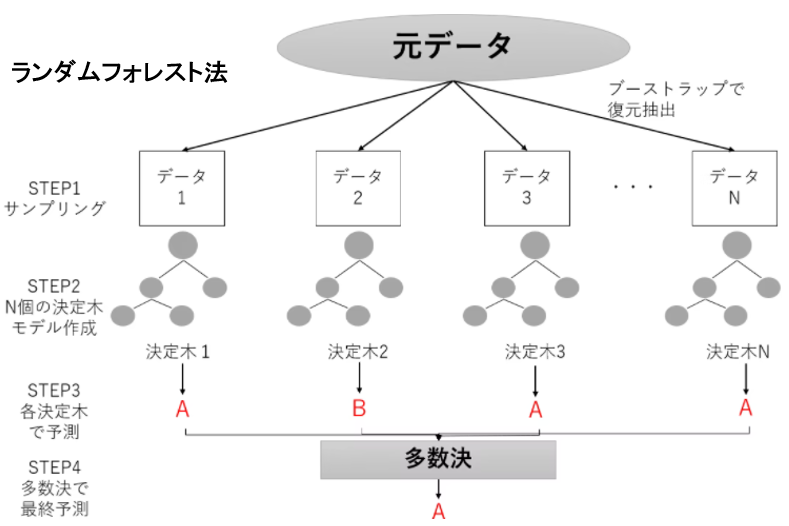

���Ă͂܂�Ɖ��߂̂��₷���̓g���[�h�I�t
�@���v�I����̕��͌��ʂ��A������Ɩ��m���̏펯�Ƃ͈قȂ邱�Ƃ�����B
�A���͌��ʂ��Ɩ��m������͉��߂��Â炢�ꍇ�́A���v�I����ŏo�����ʂ��Q�l�ɁA�����h���u���ŕ������茈����C������B
�B���f���̃f�[�^�ւ̓��Ă͂܂�ƁA���߂̂��₷���̓g���[�h�I�t�B���Ă͂܂�Ɖ��߂̂��₷���̂ǂ����D�悵�ĕ��͂��邩�ɂ���āA���͎�@��ς���B
�֘A�L��

![]() �y�g�b�v�y�[�W�֖߂�z
�y�g�b�v�y�[�W�֖߂�z![]() �yYouTubeChannel�z
�yYouTubeChannel�z![]() �y���v��͍u�`��b�z
�y���v��͍u�`��b�z![]() �y���v��͍u�`���p�z
�y���v��͍u�`���p�z![]() �yChatGPT�EPython�EExcel�z
�yChatGPT�EPython�EExcel�z![]() �y���ϗʉ�́z
�y���ϗʉ�́z![]() �y��Ó��v��́z
�y��Ó��v��́z







